Optimizers in PyPose - Gauss Newton and Levenberg-Marquadt
In deep learning, we usually use first-order optimizers like Stochastic Gradient Descent, Adam, or RMSProp.
However, in SLAM problems, we use Bundle Adjustment to jointly optimize camera pose and landmark coordinate in real time. Naive first order optimizers is not efficient enough (requires many iterations to converge) for this situation.
In this post, I will introduce the concept of second order optimizer. However, since the second order optimizer requries us to derive the Hessian matrix for the optimization target, it is usually impractical to use it directly. Therefore, we will use the Gauss-Newton and Levenberg-Marquadt optimizers instead.
Optimization Problem
The optimization problem, in general can be represented in the form of
That is, we want to find some optimal input s.t. such input can minimize some given expression .
Naive Optimization
When function is simple, we can find its Jacobian matrix (first order derivative) and Hessian matrix (second order derivative) easily.
We can then solve for . For every solution , if the hessian matrix is positive definite, then a local minimum is found.
Iterative Optimization
However, when the function is complex or lives in very high dimension (~10k in sparse 3D reconstruction problem, or ~10M in usual neural network models), it is practically impossible to solve for analytical solution of and .
In this case, we need to use iterative optimization. The general algorithm for such approach can be summarized as following:
-
For some initial guess value , we have
-
While true
-
Use the Taylor expansion of around ,
If using second-order optimizer, we have
If using first-order optimizer, we have
-
Solve for such that
- Update
- If , the solution "converges" and break out the loop
-
-
Return
First Order Optimizers
When using first order optimizer, we only use the first order derivative of to calculate . Then, we have
Obviously, the solution will be . This is aligned with the definition of naive Stochastic Gradient Descent (SGD).
Intuitively, we can interpret first order optimization as locally approximate the optimization target as a plane with form of .
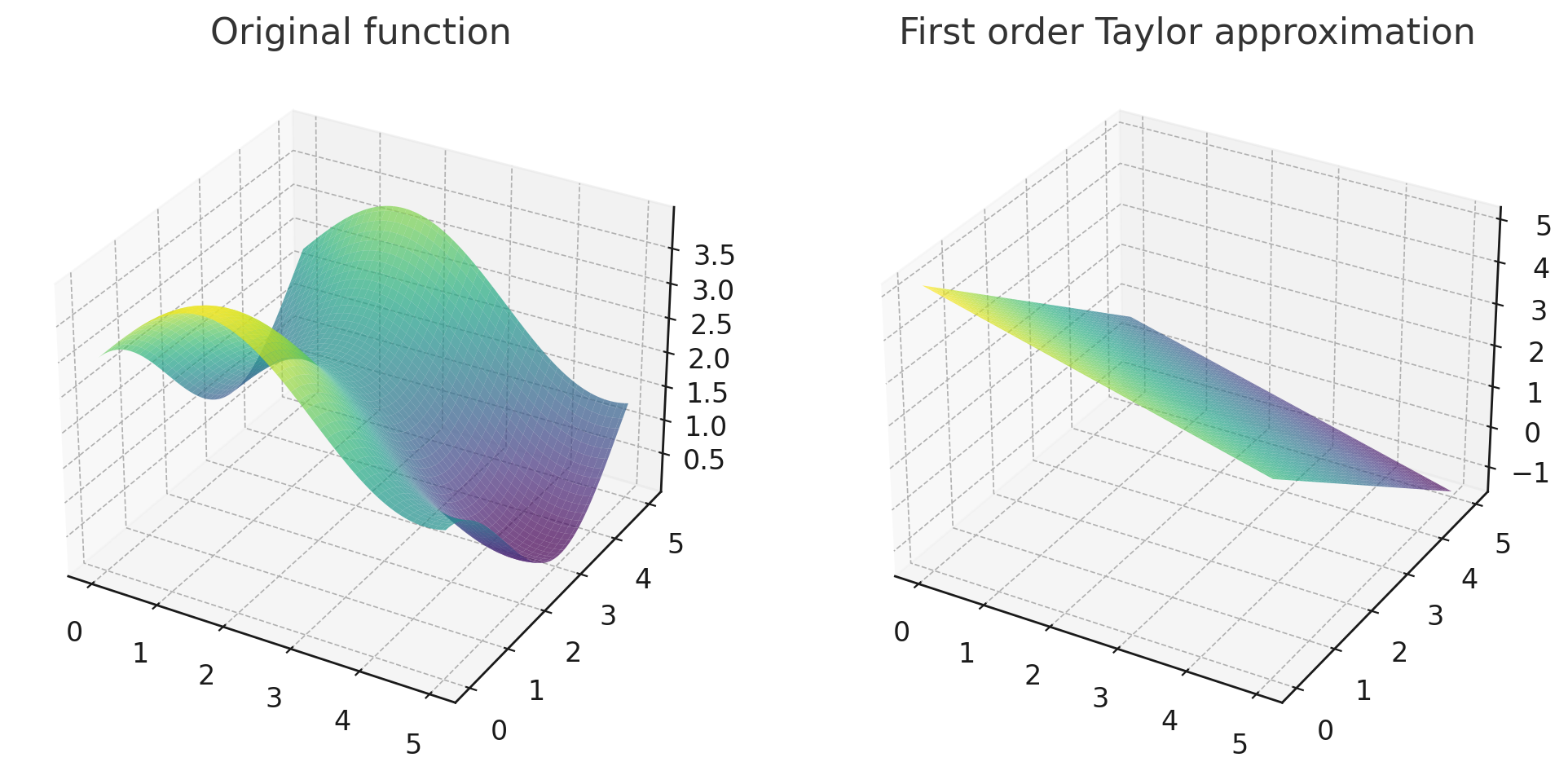
First order Taylor approximation of at . Generated by GPT-4 with code interpreter.
Such optimizer and its variants like Adam, AdamW, RMSProp are widely used in the field of deep learning and is supported by popular libraries like PyTorch.
Why not First Order Optimizer?
While first order optimizers can support large scale optimization problem, it generally requires more iterations to converge since linearization (first order Taylor expansion) is not a good approximation.
In applications like SLAM where bundle adjustments need to run in real-time, first order optimizer cannot fulfill our need.
Therefore, we have the second order optimizers.
Second Order Optimizers
The second order optimizers, specifically the Newton method uses second order Taylor expansion as the local approximation for optimization target:
Then we have
Solving
We have .
Intuitively, the second order optimizers like Newton method is using a paraboloid to locally approximate the function surface.
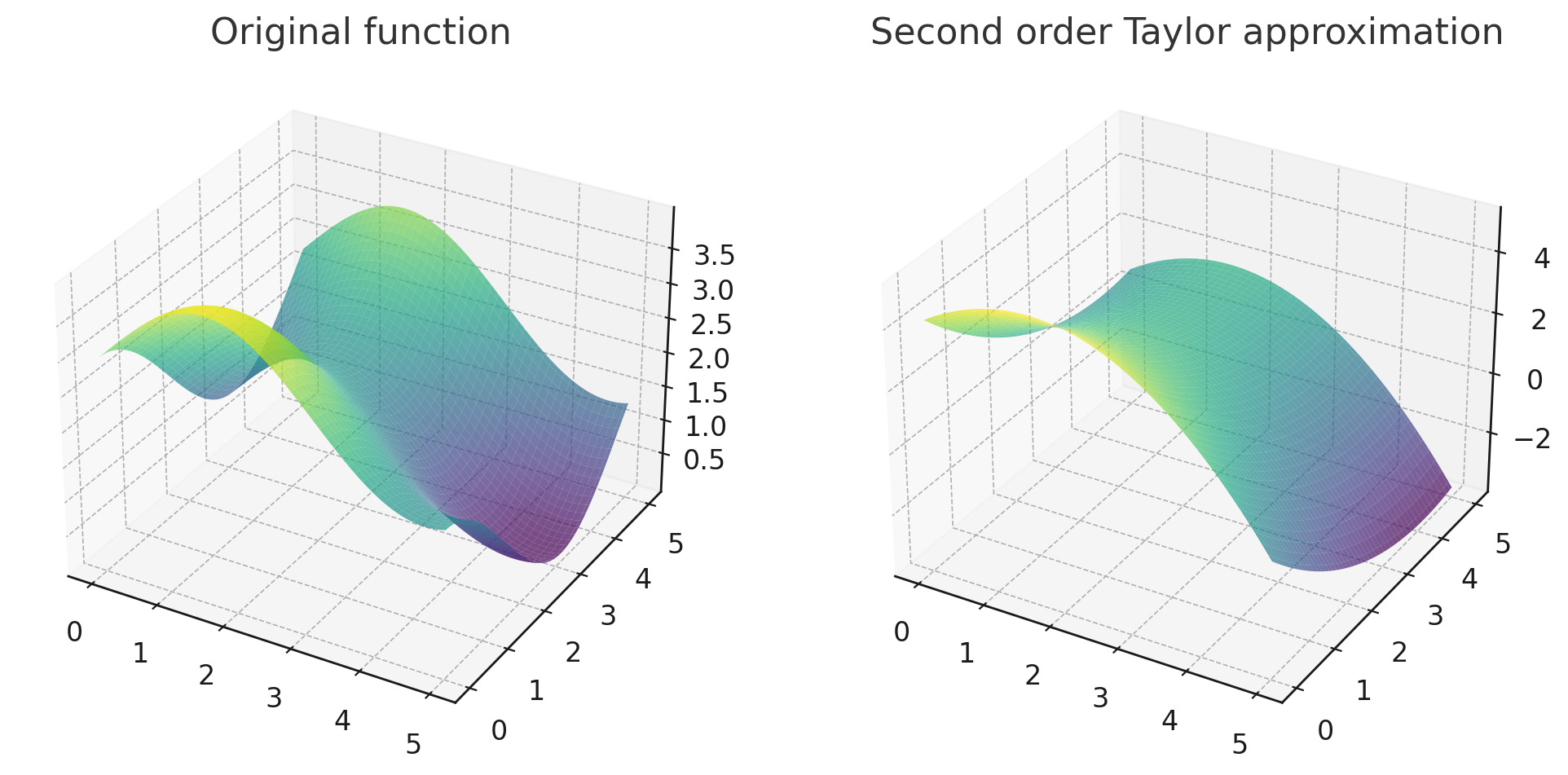
Second order Taylor approximation of at . Generated by GPT4 with code interpreter.
Why not Second Order Optimizer?
Second order optimizer provides a much better approximation to the original function. Hence, solver with second order optimizer can converge much faster than first order optimizer.
However, it is often not practical to calculate the of . If , then will have elements.
Pseudo-second-order Optimizers
Gauss-Newton Optimizer
Gauss-Newton optimizers requires the expression to be optimized to be in the form of sum-of-square. That is, the optimization target must have form of
Then, consider the first order approximation for at :
Since the term in is convex (is a square), we know the optimization target must be convex. Hence, we have when .
Hence, we have
where we can solve for .
Problem of Gauss-Newton Optimizer
In production environment, we may have not full-ranked. This will cause the coefficient matrix on the left hand side being positive semi-definite (not full-ranked). In this case, the equation system is in singular condition and we can't solve for reliably.
Also, in Gauss-Newton method, the we solved for may be very large. Since we only use the first order Taylor expansion, large usually indicates a poor approximation for . In these cases, the residual may even increase as we update .
Levenberg-Marquadt Optimizer
Levenberg-Marquadt optimizer is a modified version of Gauss-Newton optimizer.
The LM optimizer use a metric to evaluate the quality of approximation:
When the approximation is accurate, we have .
LM optimizer will then use this measure of approximation quality to control the "trusted region". The "trusted region" represents a domain where the first order approximation for is acceptable.
The update vector must be in the trusted region. Hence, the entire optimization problem is formulated as
where is a diagonal matrix constraining the in an ellipsoid domain.
Usually, the is configured as . This allows the update step to move more on the direction with lower gradient.