Build Your Own Google Drive with AWS S3
This system is deployed on My blog's file Sharing Page as a front-end application. The source code is also avalable in React-S3-Viewer Repo here.
Reference Information:
- Viewing Photo stored in S3 Buckets
- AWS SDK for JavaScript
- AWS Cognito Identity Pool
- SessionStorage - MDN
Access AWS Resources through SDK
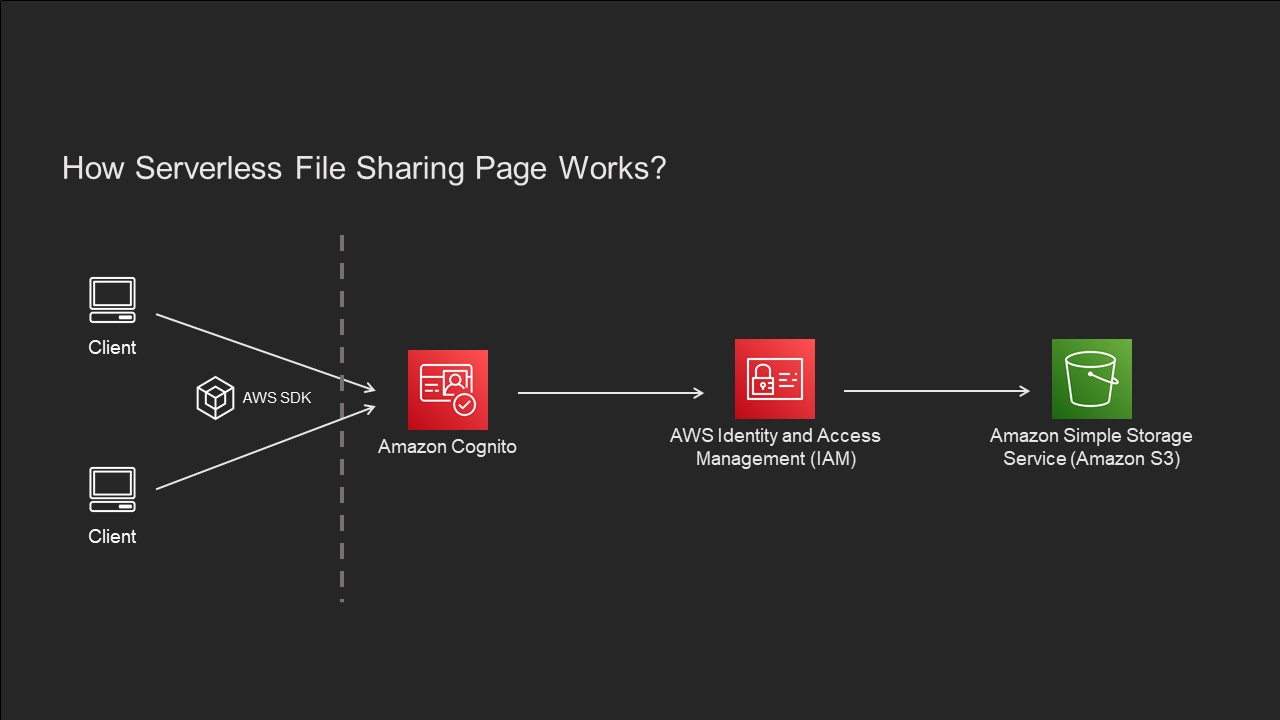
A user identity pool is created using AWS Cognito. Any user authenticated / unauthenticated join this identity pool will be automatically assigned with an AWS role. Then, we create a AWS SDK key corresponding to this identity pool. Anyone access AWS Service using SDK and given key will get an role called Cognito_MyBlogFilesUnAuth_Role.
Using IAM, we can assign this role with permission to access some specific AWS Resource. In this case, we only allow users to access the S3 storage bucket yutian-public and allow them to List and Get objects from the bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::yutian-public"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::yutian-public/*"
}
]
}
Local Caching
Since 2022 May, the file sharing page is reconstructed using React and Ant-design. Two major improvements are implemented in this latest version:
-
The file directory will be cached in the
SessionStorage. For each session, the client will only request once from the AWS. This can significantly reduce the #requests. -
When downloading, files will be cached to the
IndexDB. Therefore, unless the user reset the IndexDB or the file is updated, every file is guaranteed to be downloaded only once on each client.
File List Cache
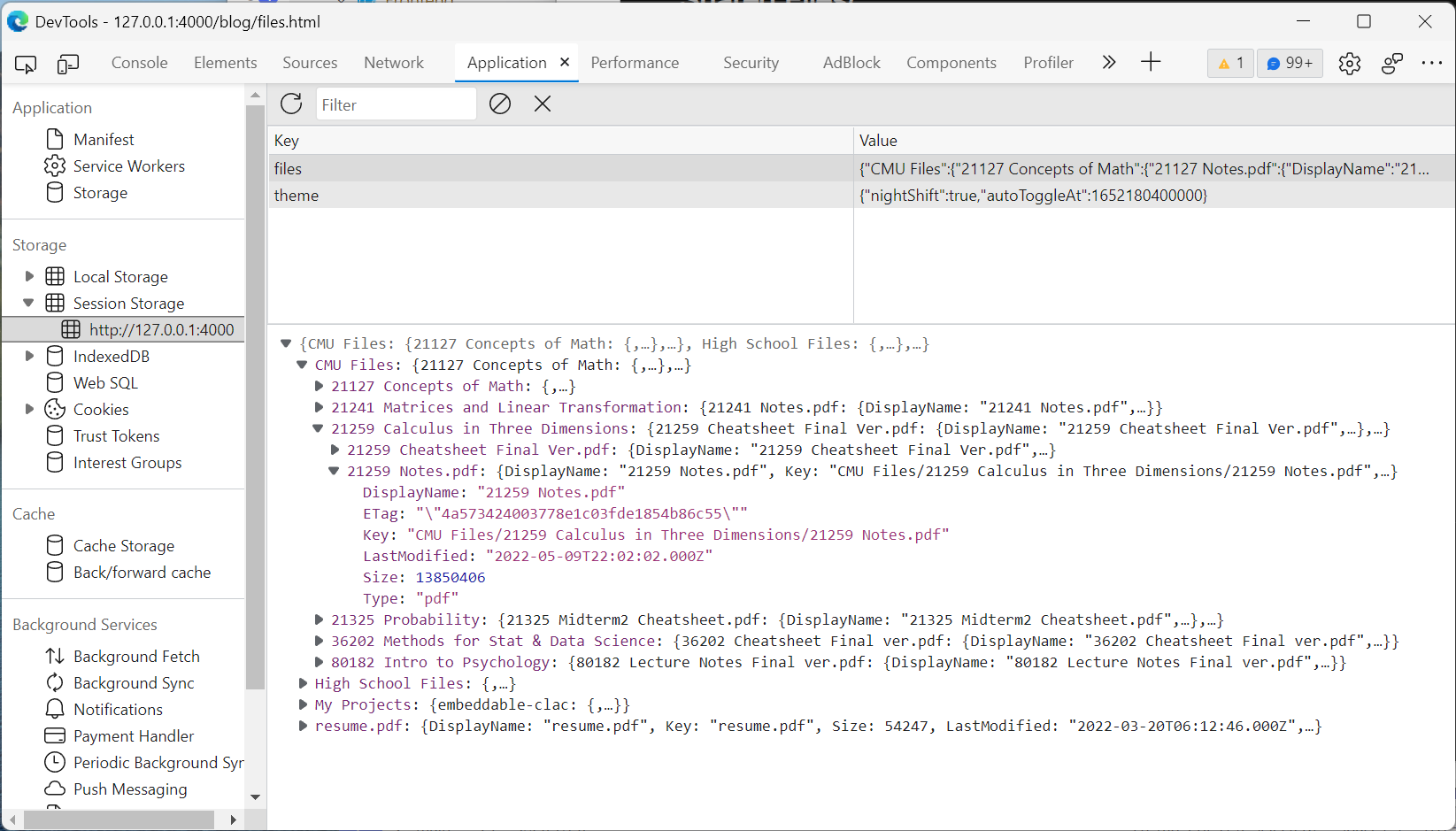
When the page is first loaded, the client will request all objects in S3 storage bucket through ListObjectV2 API. The result is a list of objects in the bucket.
There is no file structure in S3, all the "folders" are just key of object with / slashes between words. Therefore, we need to parse the result to rebuild a "file structure" back from plain list.
The file structure will then be stored into SessionStorage. Unless the user explicitly request for reload, the ListObjectV2 API will not be called anymore in current session.
File Content Cache
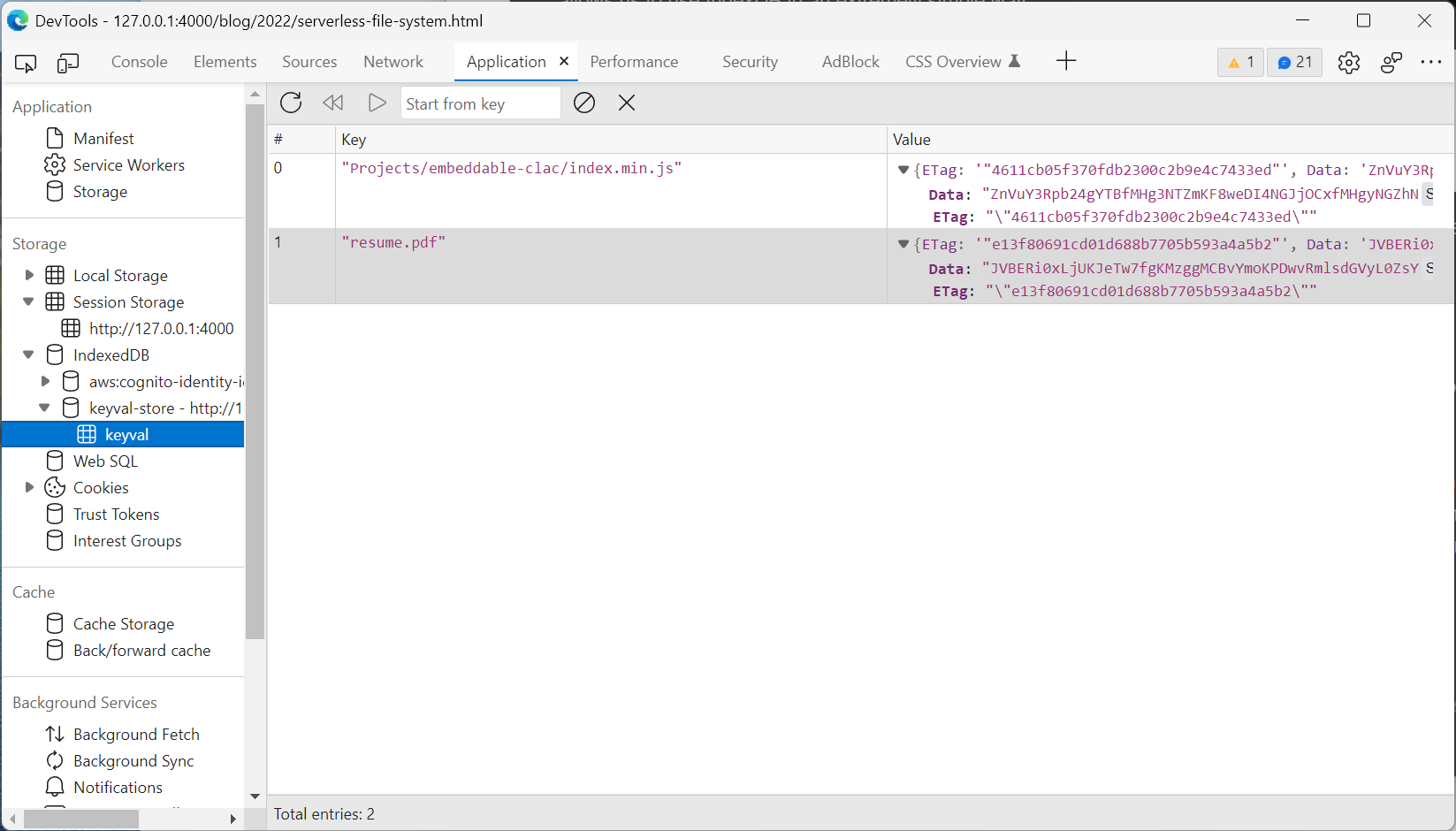
On the other hand, we want to reduce the amount of data downloaded from the AWS to minimize cost. Therefore, we want to cache the files that users has downloaded previously.
We will need to use IndexedDB since the quota for session storage is very small (~1Mb per entry). IndexedDB is much more complicated to use than SessionStorage. Luckily, there's a third-party module called idb-key-val that allows us to use IndexDB in an extremely simple way.
function set(key: string, val: any)
function get(key: string): Promise<any>
By converting Uint8Array to base64 string, we can store the file in client's cache and reduce the redundant request to AWS.
Yet, there is just one more thing
Suppose the file on S3 is updated to a newer version but the client is still caching the older version, how can the client know when to update/descard the cache?
We resolve this problem by storing the ETag field along with data. ETag is a string that reflects the change of file content (notice it's not necessarily MD5). When the key is requested, the program will also compare the ETag of requested resource and current cache. If they don't match, then a later version will overwrite the current cache.