Autonomy on the Moon - NASA Lunar Autonomy Challenge
TL;DR
This post introduces the autonomy stack we built for Lunar Autonomy Challenge (LAC) hosted by NASA. We achieved centimeter level terrain mapping precision over 200 square meters and ranked 3# over more than 20 universities.
Task Definition
The challenge asks each team to build an autonomous agent that drives a virtual lunar rover around a stationary lander and maps the surrounding terrain. The environment, rover and physics are simulated in a custom build of CARLA with a Python API. Agents are packaged as a Docker container and evaluated on a held-out environment whose ground truth is never released.
Mapping objective
The mapping area is a 27m × 27m patch of deformable regolith centered on the lander, discretized into 15cm × 15cm cells (180 × 180 = 32,400 cells). For every cell the agent must output:
- an estimated elevation, and
- a boolean flag indicating whether the cell contains a rock.
Rocks are immovable; the regolith deforms 2–3cm under the wheels and leaves visible tracks. The agent has 24 hours of mission time (virtual time inside the simulator) and 180 hours of compute time (wall-clock time on the cloud evaluator) to finish — denser perception costs compute, slower planning costs mission time.
Rover platform
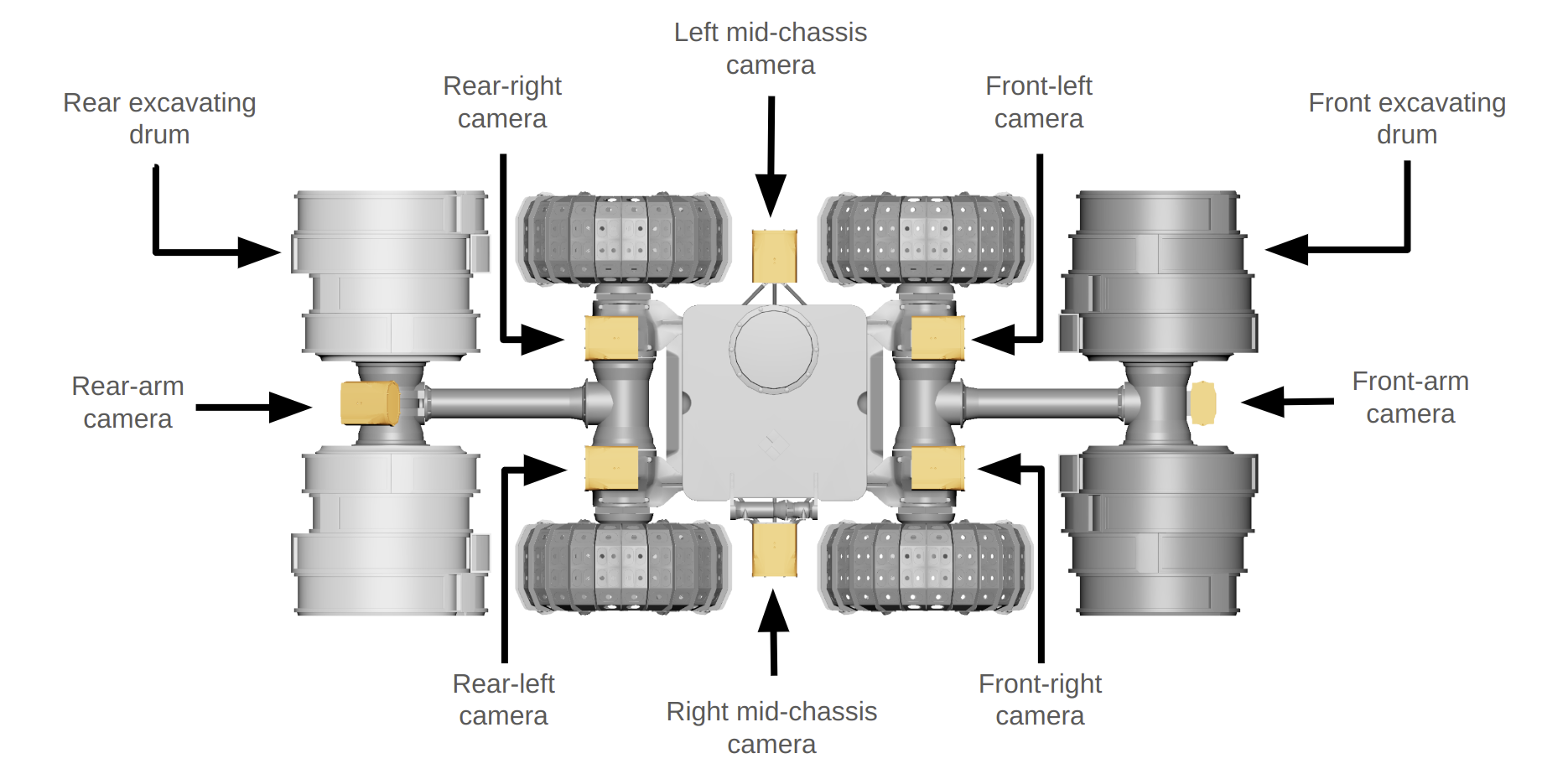
The simulated rover is based on NASA's IPEx design — a 4-wheeled differential-drive base with articulating front and rear arms. The arms can lift the chassis for a higher vantage, or be used to right the robot if it tips. Sensing is:
- 8 monochrome cameras — two stereo pairs (front, rear), two side-facing cameras, and two arm-mounted cameras. Each is paired with an LED light, can be toggled at runtime, and supports resolutions up to 2448 × 2048 px. At most 4 cameras may stream simultaneously due to a bandwidth limit.
- An IMU.
The lander itself is the only fixed visual reference at the center of the mapping area. It is optionally decorated with AprilTag fiducials; using them is opt-in, and agents that localize without them score bonus points. (We didn't use them!)
Our Autonomy Stack
Our system splits cleanly into a perception front-end that turns raw stereo images and IMU samples into a metric understanding of the world, and a planning & control back-end that decides where to drive next. Everything is plumbed through a 2D bird's-eye-view (BEV) map that doubles as both the mission output (elevation + rocks per cell) and the planner's cost map.
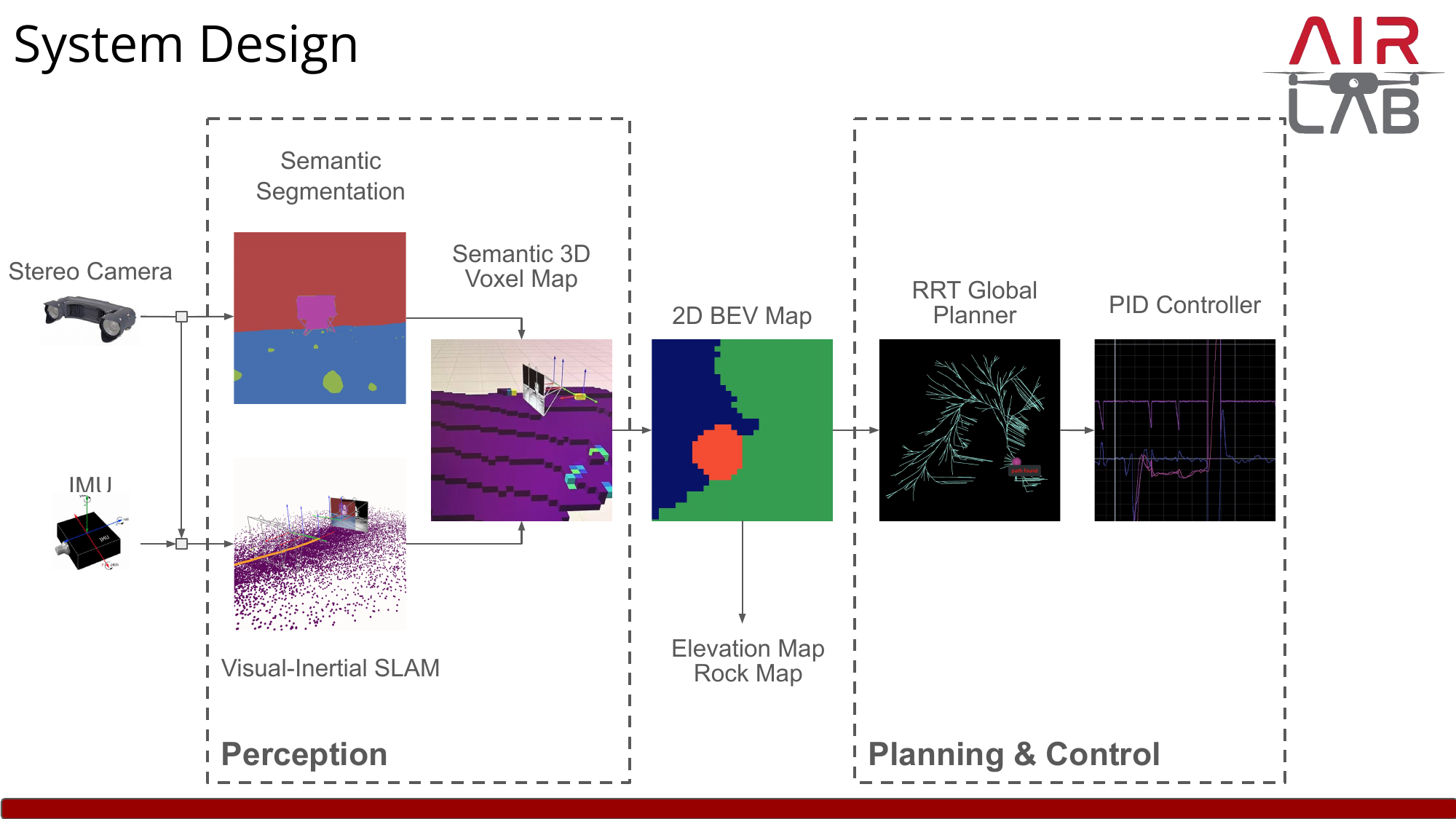
Perception
The perception module estimates rover pose, builds a 3D map of the environment, and segments rocks from regolith.
Visual-inertial SLAM. Pose estimation is the foundation of everything downstream — without an accurate trajectory, any voxel we drop into the map is in the wrong place, and small drift compounds to centimeter-scale mapping errors over a 24-hour mission. Our SLAM is built around two learning-based components we previously published:
- MAC-VO — a stereo visual odometry front-end that learns uncertainty-aware keypoint matching and metric-aware spatial covariance, so each landmark contributes to the pose graph weighted by its true measurement reliability rather than a hand-tuned constant. The matching network runs on the GPU while the optimizer runs in parallel on the CPU.
- AirIMU — a learned IMU pre-integrator that emits both an integrated motion estimate and a predicted covariance for it, again so the factor graph weights IMU constraints against visual ones based on their actual instantaneous noise rather than a constant Gaussian prior.
Both modules feed a shared factor graph that runs global pose-graph optimization with a loop closer in a separate optimizer process, producing the trajectory and a sparse mapping point cloud.
Why VIO is non-negotiable on the Moon. Lunar regolith is adversarial for visual odometry: textureless stretches, hard cast shadows, and the lander as one of the few high-contrast landmarks. Vision alone (MAC-VO) avoids catastrophic failures thanks to its uncertainty-aware matcher, but still drifts noticeably over long featureless traverses. Adding the IMU (AirIMU) closes that gap — the gyroscope's rotation stays trustworthy when the camera doesn't, and because both modules emit learned per-measurement covariances, the factor graph automatically up-weights whichever sensor is informative. The combined VIO is what lets us hit centimeter-level mapping precision over the full 27 × 27 m area for the 24-hour mission — a regime vision-only odometry can't stay globally consistent in.
Semantic segmentation. A lightweight segmentation network labels every pixel as terrain vs. rock (the simulator's other classes — robot, lander, fiducials, Earth — are masked out). Each labeled pixel, paired with its stereo depth and the SLAM pose, is projected into a global semantic 3D voxel map. Voxels accumulate class votes across frames so noisy single-frame predictions wash out.
BEV projection. The voxel map is collapsed along the gravity axis into a 2D BEV grid that aligns with the competition's required 15cm × 15cm cells. For each cell we read off the average occupied-voxel height (the elevation map) and a binary rock flag (true if any voxel in that column is labeled rock). This BEV is exactly the artifact the leaderboard scores us on.
Planning & Control
The same BEV that we submit as the mapping result also serves as the planner's cost map — rocks become hard obstacles, and the elevation gradient discourages traversing steep terrain.
- Global planner. An RRT-based global planner samples paths from the rover's current pose to the next mapping waypoint, iteratively refining toward shorter, lower-cost trajectories on the BEV. As the perception module fills in more of the map, the planner re-plans against the latest cost map.
- Tracker. A simple PID controller on linear and angular velocity follows the planned path. The differential-drive kinematics and the slow speeds we operate at make a more sophisticated model-predictive tracker unnecessary.
Lessons from implementation
A few details ate disproportionate amounts of debugging time and are worth flagging:
- Initialization. There is a non-trivial gap in mission time between the rover's reported initial pose and the first usable camera frame; bootstrapping SLAM blindly from "frame 0 = origin" produces a permanent offset. We instead align the SLAM frame to gravity using the IMU before accepting the first visual update.
- Trusting IMU rotation. The IMU's rotation estimate is excellent even when its position integration is not. Using IMU integration as the rotational prior (and only relying on vision for translation correction) noticeably improved robustness during fast turns and over featureless regolith.
- Voxel resolution. There's a real Pareto curve between voxel size, memory and mapping accuracy. Coarser than the 15cm output grid loses elevation fidelity; much finer wastes compute time we don't have. We landed on a voxel resolution that is a small integer fraction of the output cell size so BEV projection averages cleanly.
- Loop closure. Even with low-drift VO, closing a loop when the rover circles back near the lander tightens the global map enough to noticeably improve mapping scores in the corners far from the lander.